Mevro
AI-scripted brainrot explainer videos — two animated characters, TikTok-style captions synced to ~20 ms, looping gameplay backgrounds, vertical 9:16 MP4 in 2–4 minutes.
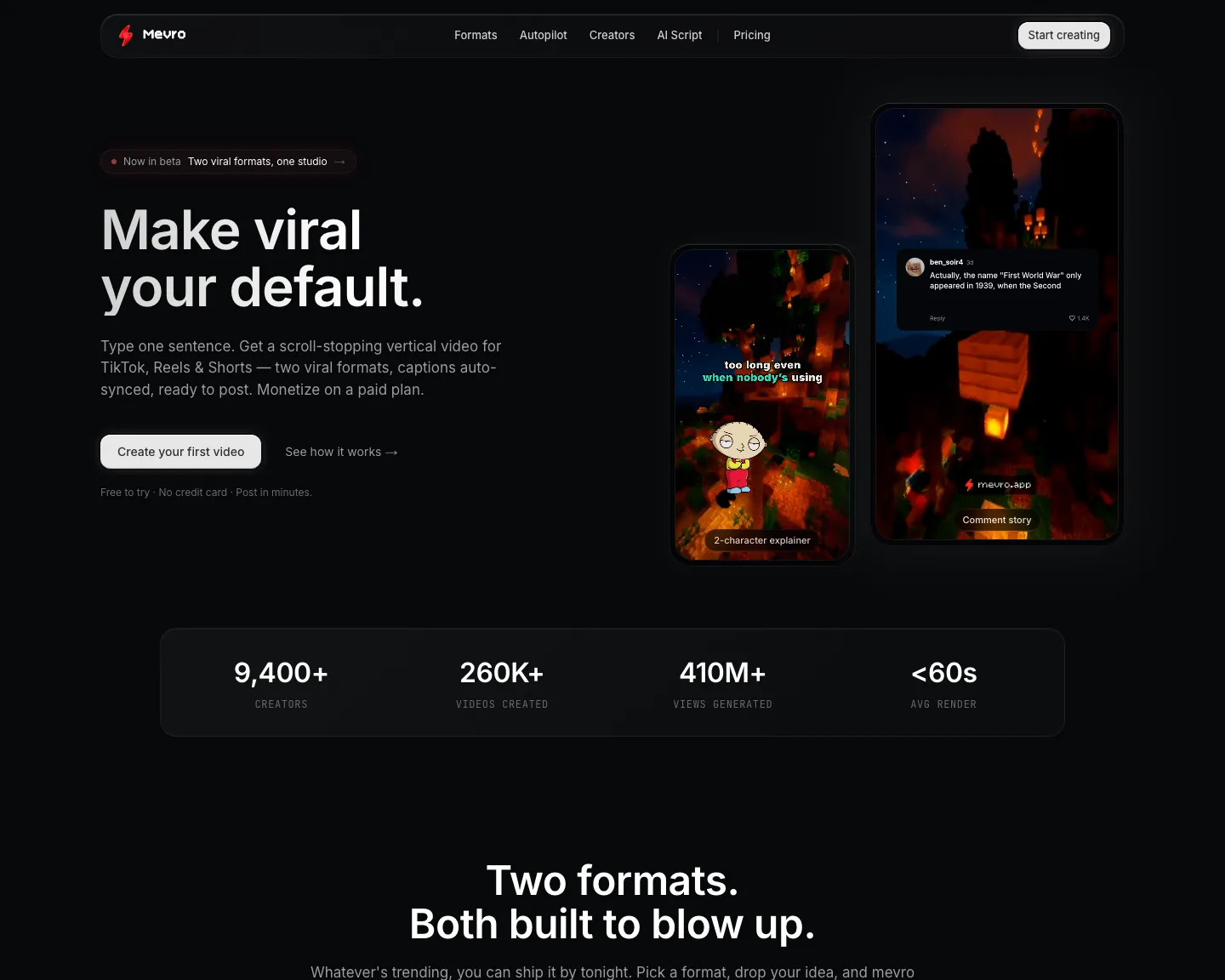
Mevro turns a topic prompt into a finished short-form video. Claude Sonnet 4.6 drafts the dialogue, two cutout characters perform it with Fish Audio TTS voices, WhisperX forced-alignment locks captions to within ~20 ms of the audio, and Remotion Lambda renders the final 1080×1920 MP4 in parallel chunks.
Built end-to-end as a creator tool: the editor lets you rewrite any line, swap voices and characters, drag captions, layer overlays, and re-render with cached audio so you only pay TTS for what actually changed.
Stateless renderer: the Remotion composition receives one JSON payload and never touches the database. That makes renders horizontally scalable and reproducible. State updates flow through Supabase Realtime, with a 3-second polling fallback while a render is active in case Realtime drops.
src/
├── app/ Next.js pages (landing, dashboard, editor, settings, admin)
├── components/
│ ├── editor/ Modal pickers (background, music, caption, character, voice, animation)
│ ├── ui/ Shared primitives
│ └── scripts/ AI Script Writer flow
├── db/
│ ├── schema.ts users · projects · messages · characters · backgrounds · music
│ │ captionStyles · credit_balances · credit_transactions · overlays
│ └── index.ts Drizzle + Postgres
├── lib/
│ ├── fishaudio.ts TTS, MP3 duration parsing, voice-library proxy
│ ├── whisperx-modal.ts Modal WhisperX endpoint caller (primary alignment path)
│ ├── caption-timings.ts Syllable estimator fallback
│ ├── audio-silence.ts MP3 → PCM speech-window detector
│ ├── render-urls.ts Signed-URL minters for Lambda S3
│ ├── credits-server.ts Atomic debit/refund logic
│ └── supabase/{server,browser,admin}.ts
├── trigger/
│ ├── generate-audio.ts TTS → WhisperX alignment with retry/refund
│ ├── render-video.ts Orchestrates audio gen → Lambda render → S3 upload
│ ├── generate-thumbnail.ts
│ └── cleanup-renders.ts Periodic S3 GC
└── remotion/
├── MevroVideo.tsx Parameterized composition (full project JSON in)
├── components/ Character · Caption · BackgroundLoop · MusicTrack · VoiceLine
├── animations.ts Entry / during / exit definitions
└── types.ts Serializable types — no functions, no Date objects
Two-character animated dialogue
Each message picks a character (custom-uploaded cutout PNG + voice). Position, scale and per-message animation are draggable in the live preview, with bulk "apply to all instances" actions.
Word-level caption sync
WhisperX forced phonetic alignment on a Modal-hosted T4 reaches ~20 ms accuracy. The source text is sent as a single segment, so output words match input 1:1 — no Whisper transcription hallucinations.
20+ caption styles
Configurable font, weight, size, transform, letter spacing, per-word color cycles, background pills, stroke and shadow. Per-word colors render via index, so gradients and rainbows have zero per-frame CPU cost.
AI Script Writer
Claude 4.6 generates 4–8 message scripts from a topic prompt with tool-forced JSON. Editable line-by-line before rendering.
Cache-aware TTS
Audio is cached by hash of provider + text + voice + temperature + top-p + speed. Re-renders only re-synthesize the messages you actually changed — the main cost lever.
User-uploaded characters & music
Custom PNG/JPG/WebP cutouts (≤5 MB) with fal.ai background removal, plus MP3/WAV/M4A music (≤20 MB). Backgrounds remain admin-seeded for IP safety.
- 01
Render request
Editor calls
renderProject(projectId); credits debit atomically inside a Postgres transaction with a queued refund row on failure. - 02
Trigger.dev task spawns
render-videofires with payload{ projectId, userId, creditCost }and pre-filters audio: each message's cache key is checked against expected. - 03
Batch audio generation
Stale messages dispatch
generate-audiosubtasks in parallel batches of 5 viabatchTriggerAndWait. - 04
TTS + alignment
Fish Audio synthesizes MP3 → music-metadata parses duration → audio buffer + source text go to Modal WhisperX → word timings written to the message row.
- 05
Lambda render
Once all audio is ready, the task marshals the full project JSON and invokes Remotion Lambda. Frame ranges are sized to stay under the AWS concurrency cap.
- 06
Sign & notify
MP4 uploaded to private S3, signed URL minted (24 h editor / 1 h share / 7 d email),
projects.outputUrlset, status flipped to"ready", Realtime UPDATE swaps the editor canvas to the video player.
Forced alignment, not transcription
WhisperX is called with the source text as one segment. No speech-to-text means no word-mismatch — captions always match what the script says.
Atomic credit debits + compensating refunds
Credits debit before the render task fires. onFailure (after retries exhausted) inserts a refund row idempotently; catchError only updates progress.
Modal scale-to-zero GPU
WhisperX endpoint auto-scales to zero between renders. Cold-start pays only CUDA init + GPU model load — model weights baked into the Docker image. ~$0.0002 per render.
Realtime + 3-second polling
The editor subscribes to project/message Realtime channels but reconciles via polling while rendering — Realtime can drop on JWT expiry, backgrounded tabs, or flaky networks.
Stateless renderer
Remotion composition reads one JSON payload, never the DB. Reproducible renders and easy horizontal scaling.
Per-tier signed URLs
Editor links last 24 h (full context), public share pages get 1 h (anonymous, can't re-render), email links last 7 d for permanent notifications.
The decisions that shaped this build, and what each one cost.
WhisperX forced alignment over speech-to-text
Forced alignment guarantees 1:1 word match against the source script — no caption hallucinations. Cost: a Modal GPU call on every render. Worth it because caption mismatch is a content-killing bug.
Remotion Lambda over self-hosted ffmpeg
Lambda gives parallel-chunk rendering with zero ops. Costs more per render than self-hosting — but the alternative is owning a video infrastructure problem this product doesn't need yet.
Cache audio by hash, not regenerate
Caching by provider + text + voice + settings hash saves ~80% of TTS cost on iteration. The cost: "force regenerate" UX is harder, and stale cache keys must be detected during prep.
Realtime + 3-second polling, not Realtime alone
Realtime drops on JWT expiry, backgrounded tabs and flaky networks. Adding polling reconciliation while rendering means the editor never gets stuck mid-render — at the cost of duplicate event handling logic.
- 10 free credits on signup
- Unlimited projects within balance
- Preset characters, backgrounds, captions, music
- 3–4 preset character voices
- Full Fish Audio voice catalog (500+)
- Custom caption styles, characters, music
- Priority rendering (schema-ready)
- Advanced animations & overlays
Stage: In development. MVP ships one format (two-character explainer). Deferred: multi-format choice, voice cloning, metered per-second billing, public discovery dashboard.
The same primitives that make Mevro work make enterprise platforms work.
Atomic credit debits with compensating refund rows are the same pattern as audit-grade financial transactions in regulated software. Trigger.dev's queued retry semantics translate directly to Mendix scheduled events and microflow async processing. Per-tier signed URLs (1 h share / 24 h editor / 7 d email) are how any serious platform partitions asset access — and the kind of thinking required for SSO-bound document portals or maritime certification systems.